1. 证明 Attention 的 $O_i$ 只与 $Q_i$ 有关
Attention 的公式如下:
$$ O=Attention(Q,K,V)=softmax\left(\frac{QK^T}{\sqrt{d_k}}\right)V $$假设 $Q=\begin{bmatrix}Q_0\\Q_1\end{bmatrix}$, $K=\begin{bmatrix}K_0\\K_1\end{bmatrix}$
那么:
$$ O=softmax(\frac{\begin{bmatrix}Q_0K_0^T&Q_0K_1^T\\Q_1K_0^T&Q_1K_1^T\end{bmatrix}}{\sqrt{d_k}})V $$令:
$$ A=\begin{bmatrix}A_0\\A_1\end{bmatrix}=\begin{bmatrix}Q_0K_0^T&Q_0K_1^T\\Q_1K_0^T&Q_1K_1^T\end{bmatrix},f(x)=\frac{softmax(x)}{\sqrt{d_k}} $$此时, $A_1$ 只和 $Q_1$ 有关, 和 $Q_0$ 无关, 那么:
$$ \begin{bmatrix}O_0\\O_1\end{bmatrix}=O=\begin{bmatrix}f(A_0)\\f(A_1)\end{bmatrix}V=\begin{bmatrix}f(A_0)V\\f(A_1)V\end{bmatrix} $$因此, $O_i$ 只和 $A_i$ 相关, 而根据 $A$ 的设定, $A_i$ 只和 $Q_i$ 相关, 即:
Attention 矩阵的第 $i$ 个输出只和第 $i$ 个 $Q$ 有关, 和之前的 $Q$ 无关.
总结:
- 在预测下一个 token 时,只需对新 token 计算对应的
Q_new,并与之前已经缓存的K_cache和V_cache进行注意力计算。 - 新的
K_new和V_new会被加入到缓存中,继续为下一个 token 生成提供基础。 - 整个过程避免了对所有历史 token 的重复计算,大幅提高了效率。
2. KV Cache 的增量过程
2.1. 初始输入(完整序列)计算:
- 对于初始的输入序列
(seq_len, embed_dim),我们通过线性变换得到Q、K和V,它们的形状都是(seq_len, embed_dim)。 - 使用
Q和K进行点积计算注意力分数,然后结合V计算得到输出(seq_len, embed_dim),这是第一次对初始序列的完整计算。
2.2. 预测下一个 token 时的增量计算:
在预测下一个 token 时,不需要对整个序列再进行完整的 Q、K、V 计算,而是只需对新生成的 token 进行一次增量计算。这时的操作流程如下:
- 输入新的 token:将已经生成的 token(其形状为
(embed_dim,))作为输入,通过线性变换得到该 token 对应的Q_new,形状为(embed_dim,)。 - 与之前缓存的
K和V进行注意力计算:使用Q_new与之前已经计算并缓存的K_cache和V_cache进行注意力计算。这里的K_cache和V_cache分别是之前每次生成 token 时得到的K和V,它们的形状是(seq_len, embed_dim),即缓存了从最初输入序列到当前已经生成的所有 token 的K和V。Q_new可以直接与K_cache进行点积,得到注意力分数,然后结合V_cache得到新的输出。 - 更新
KV Cache:新的K_new和V_new会通过线性变换得到(形状为(embed_dim,)),并将它们添加到K_cache和V_cache的末尾,使得缓存的K_cache和V_cache不断增大,以备后续使用。 - 输出:通过注意力计算后的输出形状为
(embed_dim,),即新生成的 token。
4. vllm 中的 Paged Attention
4.1. 动机: Memory Wastes
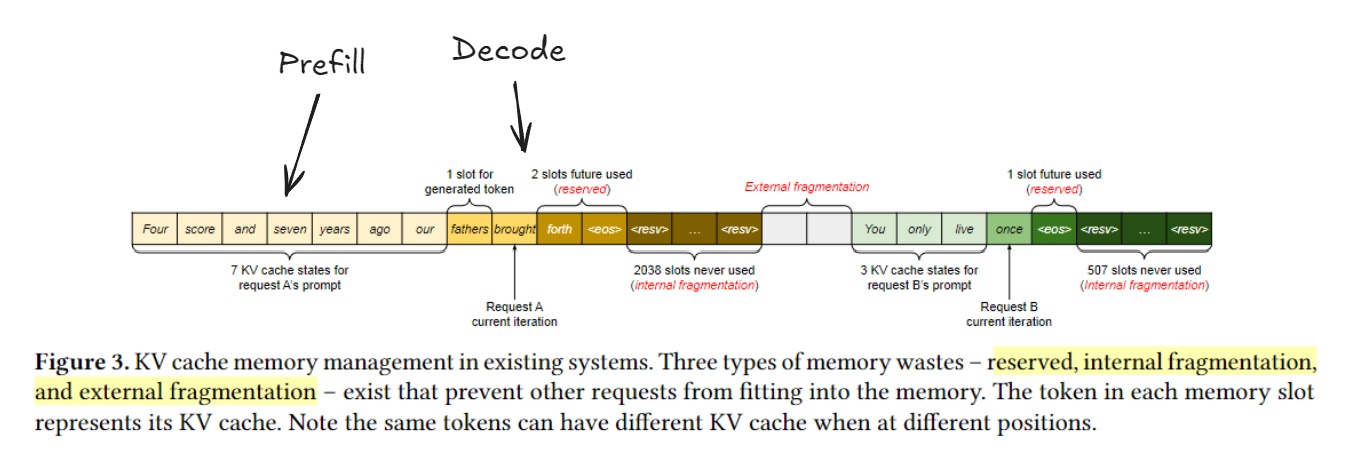
上图展示了可能的内存浪费情况, 主要时输入 sequence 不知道 eos 在哪里, 如果随机申请内存, 可能导致大量内存碎片, 因此吞吐量下降.
4.2. 解决方案: 用 Page 管理内存
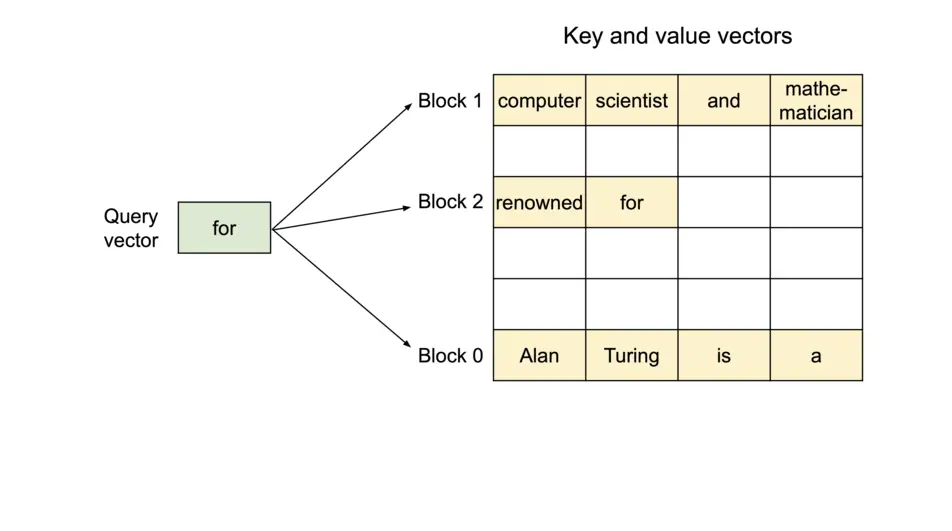
上图展示了 vLLM 用 Paged 管理内存具体怎么做的.
简单来说, vLLM 在开始推理前为每个 Decoder Layer 申请两个巨长的 Tensor (k_cache 和 v_cache), 把 Tensor 分割成连续等长的 PA blocks (图中的一行为一个 PA Block); 每个 PA Block 能够存放 BLOCK_SIZE 个 token 的 K 或 V cache (每个 cache 的形状可以理解为 (num_heads, head_size)).
因此, k_cache 和 v_cache 的形状可以理解为 (num_blocks, num_heads, head_size).
对于一个连续的 sequnce, 在 prefill 阶段前就会分配好它的 PA blocks, 之后推理时:
- 若是计算 prompt 的 Attention, 则先把传入的 K 和 V 按照 PA blocks 存入
k_cache和v_cache中; 然后利用整段的 QKV 计算 attention. - 若是计算新 token, 则利用 Q 和 block table 计算 decode 阶段的 attntion; 此时访存的就是
k_cache和v_cache中的 PA blocks.
5. Paged Attention Kernel 详解
References:
先看下整体计算流程图 (这个图后面也会出现这里先看一眼):
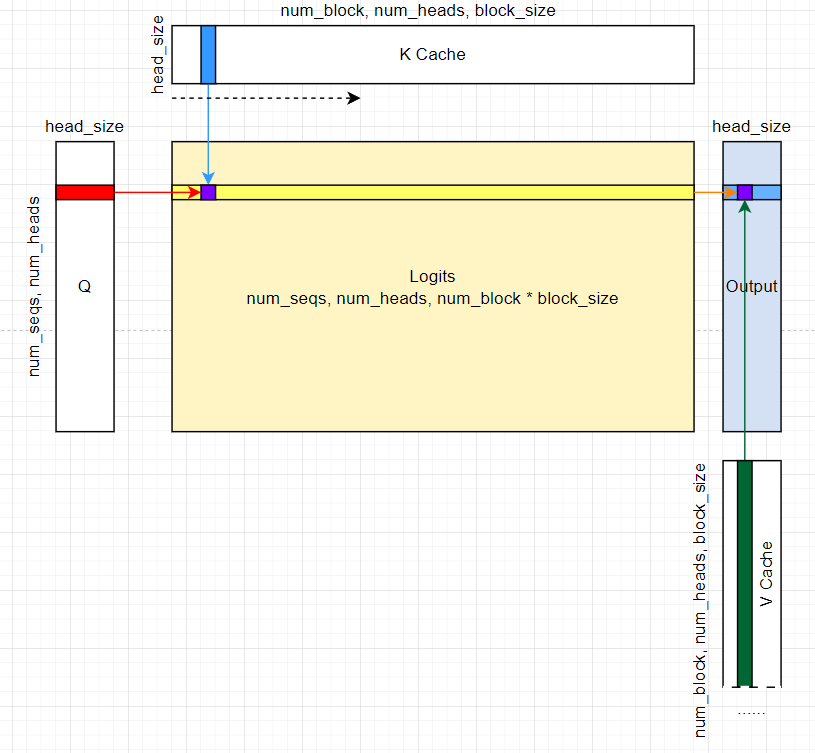
5.1. 输入输出输出分析和参数说明
| |
模板参数说明:
scalar_t元素类型 (实际代码中还有cache_t表示 KV cache 的元素类型).HEAD_SIZE每个 head 中元素数量.BLOCK_SIZE每个 PA block 中的 token 数量.- KV cache 被存储在不同 PA blocks. 每个 PA block 存储一个 head 中
BLOCK_SIZE个 token.
例如, 若BLOCK_SIZE=16,HEAD_SIZE=128, 则一个 PA block 能存储一个 head 的16 * 128 = 2048个元素. - 每个 PA block 可能只包含一部分的 context tokens.
- 从 page 角度看, KV cache 是若干个 page 的集合;
- KV cache 被存储在不同 PA blocks. 每个 PA block 存储一个 head 中
NUM_THREADS每个 CUDA thread block 中 thread 的数量.PARTITION_SIZE参与 TP 的 GPU 数量, 默认 0 表示单卡. (以下都以单卡为例说明)
额外的一些参数:
num_seqs: 本次推理请求 sequence 数目.由于这个 kernel 只处理 decode 阶段单 query attention, 所以实际上每个 sequence 只有一个 query token.
num_heads: Q 的 head 数目num_kv_heads: KV 的 head 数目, 对于 MHA 其值和num_heads相同; 如果是 GQA, MQA 则num_kv_heads小于num_head.head_size: 即HEAD_SIZEk_cache: (num_blocks, num_kv_heads, head_size/x, block_size, x), 其中x表示THREAD_GROUP_SIZE * VEC_SIZE的大小 (后面会细说).
下面结合 GPU architecture 初步分析一下参数.
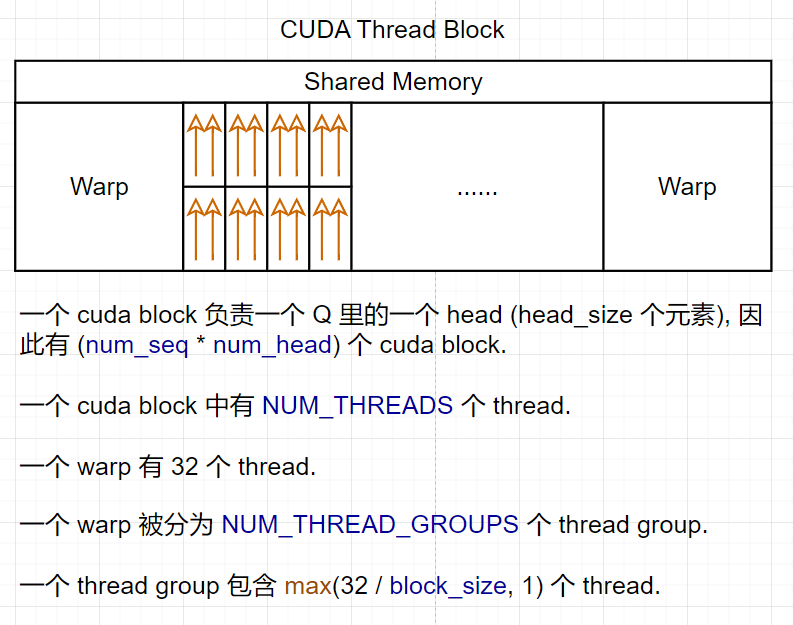
🧐 为什么要分 thread group?
- 因为当一个 cuda block 要取的数据比较少的时候 (计算 QK), 一个 thread group 分别一次取 Q 和 K 中 16B; 当一个 cuda block 要取的数据比较多的时候 (计算 LV), 一个 thread 取 16B.
5.2.Shared Memory: q_vecs 的写入
从 kernel 中的第一个申请的 shared memory 开始说.
关于 shared memeory:
- 在 kernel 中申请的 shared memory 被当前 cuda block 中的所有 thread 共享.
- shared memory 的作用是为了减少 global memory 的访问次数,提高访存效率.
以下代码申请了一块 shared memroy 被整个 CUDA Block 中所有 kernel 共享:
| |
首先, q_vecs 覆盖了 Q 中 head_size 个元素 - 这也是一个 cuda block 需要处理的数据量.
接着再说两个维度的参数的意思:
| |
THREAD_GROUP_SIZE: 每个 thread group 中的 thread 数量. 注意, 一个 cuda block 中有NUM_THREADS个 thread,NUM_THREAD_GROUPS个 thread group.THREAD_GROUP_SIZE = MAX(WARP_SIZE/BLOCK_SIZE, 1).NUM_VECS_PER_THREAD:HEAD_SIZE能被分成多少个 16B. (这个变量这么命名的理由是后面读取 K 的时候每个 thread 会往自己的寄存器内读NUM_VECS_PER_THREAD个 k_vec.)
证明:
q_vecs覆盖 Q 的一个 head, 并且NUM_VECS_PER_THREAD表示 Q 的一个 head 被分成多少个 16B.
=>THREAD_GROUP_SIZE*VEC_SIZE= 16B /sizeof(scalar_t);
=>NUM_VECS_PER_THREAD* 16B /sizeof(scalar_t)=HEAD_SIZE;
然后看 load Q 的代码, 建议结合下面的图一起看:
| |
thread_group_idx表示当前 thread 属于当前 cuda block 中第几个 thread group.thread_group_offset表示当前 thread 在当前 thread group 中是第几个 thread.
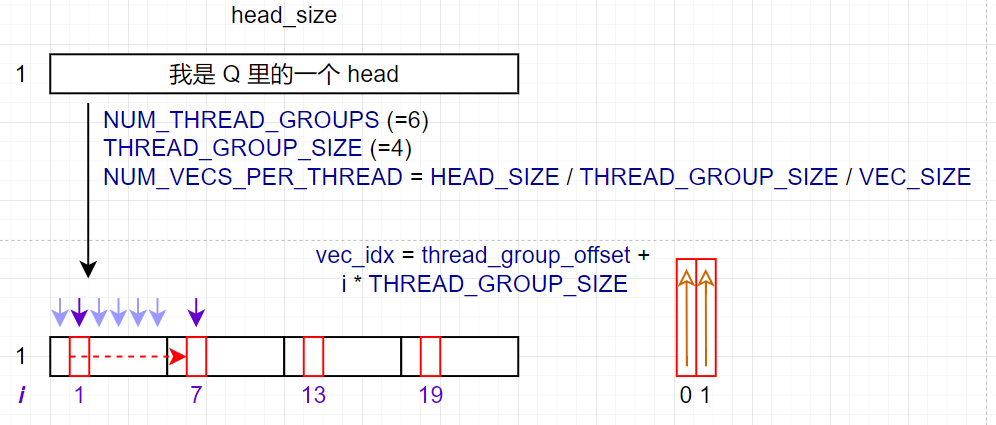
上图展示了循环具体是怎么跑的.
- 一个紫色箭头表示一个 thread group.
NUM_VECS_PER_THREAD表示HEAD_SIZE能被分成多少个 16B.- 实际读取 Q 的内存时, 所有 thread group 从 Q 的起始位置紧密排列, 根据图上看的话一共有
NUM_THREAD_GROUPS个紫色箭头. - 所有 thread group 读取一次 Q 并存入
q_vecs对应循环中的一次迭代; 因此下次迭代 thread group 需要向后偏移NUM_THREAD_GROUPS个位置 (例如i从 1 变为 7). - 此外, 读一次 16B 对应一个 thread 来说自然也是取一个 VEC.
- 对应到 kernel 编写, 还需要计算当前 thread 具体读取哪个 vec; 因此得到
vec_idx = thread_group_offset + i * THREAD_GROUP_SIZE.
🤔 这里会不会有 bank conflict?
总之现在我们把 (1, head_size) 大小的元素读到了 cuda block 共享的 shared memory q_vecs 中.
5.3. 读取 K Cache 并计算 QK
现在从 cuda block 的角度看, 当前 block 已经获得了自己要算的 Q 中的一个 head (形状为 (1, head_size)), 接下来就是计算 Q 和 K 的点积.
点积过程是把当前 block 拥有的 Q head 和整个 K Cache (迭代地) 进行点积运算. 参考下图:
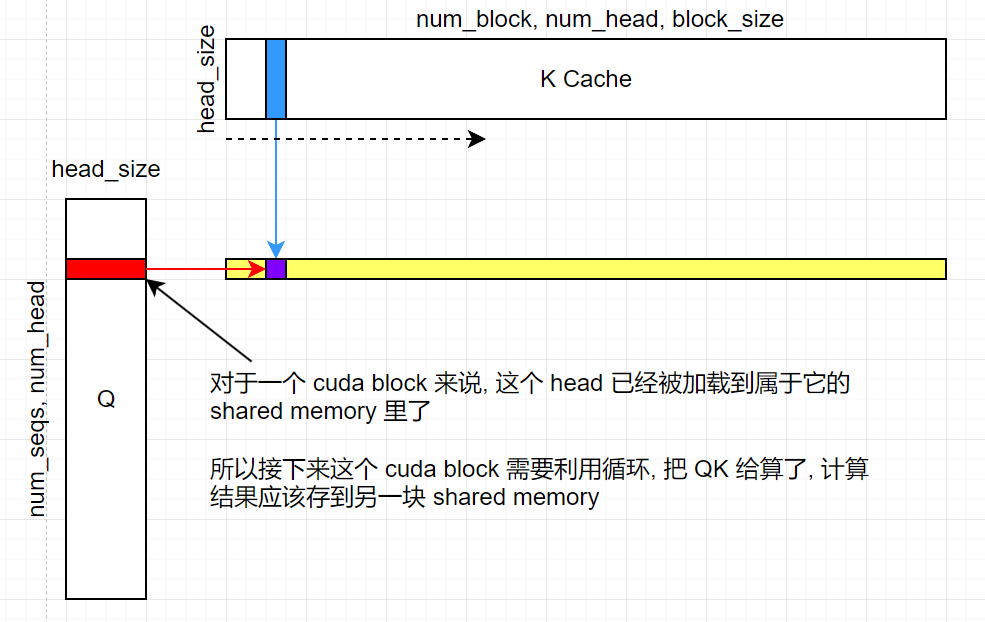
QK 乘积实际上被暂存在 logits (也是一块 shared memory) 中, 之后会被用来计算 softmax.
😇 看下循环的具体代码吧:
| |
先说第一个循环, 其中比较重要的几个参数定义如下:
| |
用文字描述就是:
blk_idx表示当前 thread 所在 warp 需要处理的 PA block 的在block_table中索引 (逻辑上的索引).start_block_idx和end_block_idx表示当前 cuda block 需要处理的 block 范围.num_blocks表示当前 cuda block 需要处理的 block 数量.NUM_WARPS表示当前 cuda block 中 warp 的数量. 一个 warp 包含 32 个 thread.warp_idx表示当前 warp 在当前 cuda block 中的索引.
说人话就是每个 warp 处理一个 PA block, 一开始 cuda block 中的所有 warp 紧密地指向最前面的 NUM_WARPS 个 PA block, 每次循环所有 warp 向后偏移 NUM_WARPS 个 PA block 的长度. 参考下图:
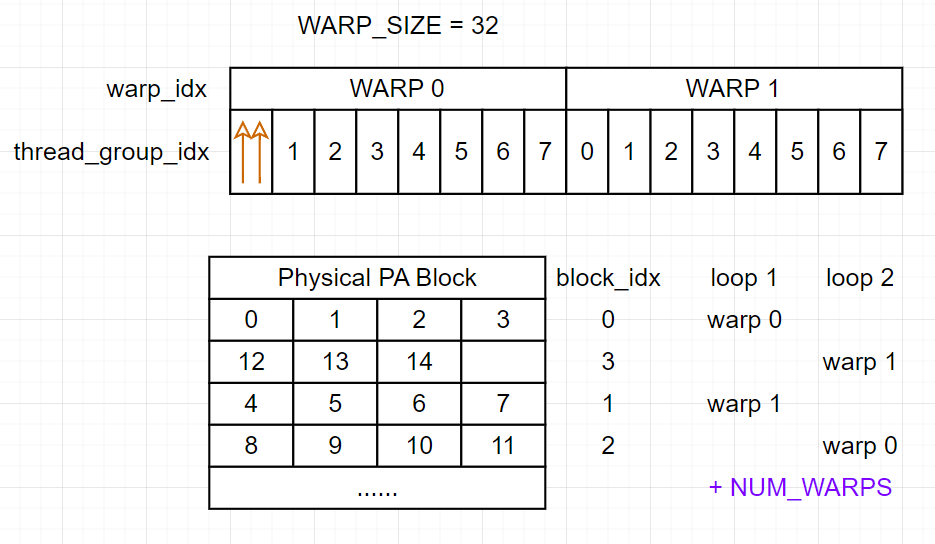
🔔 这里再回顾一下, 一个 PA block 里存放了
BLOCK_SIZE个 token 的 K 或 V cache.
所以说这个循环和上面读取 Q 的循环一个尿性🤮, 不过是以 warp 的粒度处理数据;
进入了第一个循环内部, 第一步当然是计算当前 thread 对应的 warp 应该计算哪个 PA block (物理上的索引), 因此得到了 physical_block_number:
| |
然后解释第二个循环, 第二个循环的整体目标就是让当前 warp 计算好自己负责的 PA block 中 BLOCK_SIZE 个 token 的 QK 乘积.
先看一下 i 的上界:
| |
从 kernel 角度看, 每个 thread 需要辅助当前 warp 计算自己负责的一整个 PA block (包含 BLOCK_SIZE 个 token), 而我们把这个过程拆分为 Loop 2 中的 NUM_TOKEN_PER_THREAD_GROUP (也就是 ceil(BLOCK_SIZE / 32)) 次循环;
说人话就是一个 thread group 对应一个 token 中的一个 head, 如果 BLOCK SIZE 太大了后面每个 thread 向后偏移 i * WARP_SIZE 个 token 继续狠狠算🤣.
也因此第二个循环内部一上来先计算了几个偏移量, 并且申请了 thread 内部私有的 k_vecs 数组:
| |
thread_group_idx表示当前 thread group 在整个 cuda block 中的索引.- ☢️ 一个 thread group 在一次循环中负责 fetch 一个 PA block 中 K cache 的一个 token 中自己负责的 head.
- ☢️ 一个 thread group 负责计算一个 qk 值; 这个值显然是由一个 Q head 和一个 K head 点积得到的.
physical_block_offset表示当前要算的 token 在当前 PA block 中的偏移量 (注意和前面的physical_block_number区分).- 加
i * WARP_SIZE的原因是如果BLOCK_SIZE大于 32, 那么一个 warp 要多次循环才能处理完一个 PA block 中的所有 token, 对应thread_group_idx需要做偏移. token_idx表示当前要算的 token 在整个 seq 的 KV cache 中的索引.k_vecs中能存放NUM_VECS_PER_THREAD个 VEC, 而一整个 thread group 中所有的 thread 的k_vecs合起来才能组成一个 K 的 head (推导参考上面 Q 的 😇). 这就是为什么后面算 QK 的时候要 reduce.
🤔 看到这里读者可能有一个问题: 一个 token 的 K cache 应该对应多个 head, 为什么上面说一个 thread group 只负责一个 head?
答: 因为实际计算的时候, 一个 cuda block 只负责计算一个 head, 对应到 K Cache 乃至后面 V Cache 的位置也是一样的.
这里额外说一下, 读 K 的 head 的一个目标应该是在尽量少的 register 中装下一个 head 的所有元素, 这样后续和 shared memory 中的 Q 做点乘并规约的速度更快. 假设一个 head 有 128 个 float16, 则占用 256B, 而 A100 中一个 thread 最多能有 255 个 32-bit register (也就是 1020B), 此时可以认为一个 thread 能装下一个 head 的所有元素.
但是由于目前 PA kernel 在BLOCK_SIZE为 16 的情况下THREAD_GROUP_SIZE等于 2, 因此一个 thread 只会装一个 head 的一半元素, 这样可能会导致 register 的使用率不高.
接着进入第三个循环, 目的是让 thread group 从 K cache 中读一个 head, 并存入 k_vecs 中:
| |
老规矩, 先看 j, 本质就是从 0 迭代到 NUM_VECS_PER_THREAD, 每次迭代当前 thread 读取一个 VEC 存入 k_vecs 中.
🔔 回顾:
NUM_VECS_PER_THREAD表示一个 head 被分成多少个 16B.k_cache的 shape 为(num_blocks, num_kv_heads, head_size/x, block_size, x).
其中的 x 表示一个 thread group 需要读取的元素数量 (VEC_SIZE * THREAD_GROUP_SIZE); 因此作者将 K Cache 的 layout 的最后一维设置为 x 其实也是方便后续 thread group 对 K cache 的读取.
下图具体展示了寻址的过程:
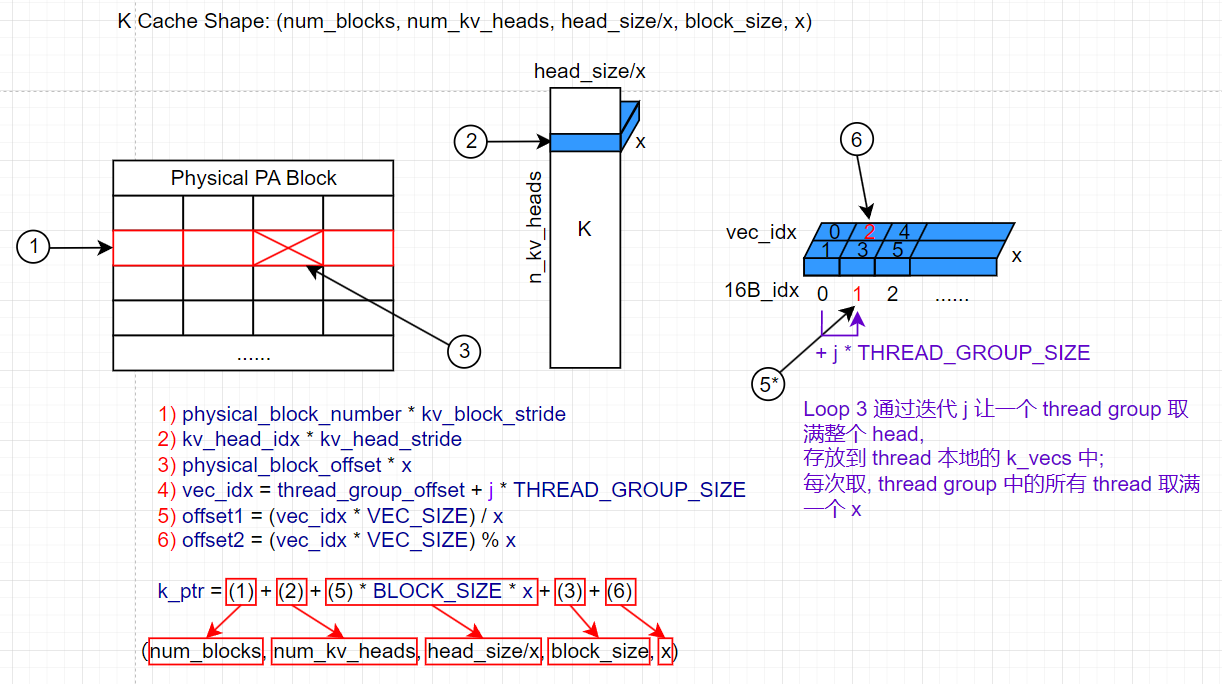
其中:
- 在 MHSA 中,
num_kv_heads等于num_heads; 而在 GQA, MQA 中,num_kv_heads小于num_heads. - (1) 负责找到当前 thread 属于的 warp 要处理哪个 PA block.
- (2) 负责找到当前 thread 要计算的 head 在 K cache 中的位置. 这个 head 的索引和 Q 中 head 的索引在 MHSA 中相同.
- (3) 负责找到当前 thread group 要计算的 token 在当前 PA block 中的位置.
- (5) 负责找到当前 thread 在需要读取的 head (蓝色长方体) 中 x 的偏移, 通过
j进行迭代读取. 每次循环 thread group 中的所有 thread 取一个 x. - (6) 负责找到当前 thread 在 thread gruop 中读取的 x 中 VEC 的偏移; thread 一次读取一个 VEC.
🤔 为什么 (5) 在实际寻址时需要 * BLOCK_SIZE * x ?
答: 这是根据 k_cache 的 layout 得到的 stride. 同理 (3) * x 也是 stride.
第 3 个循环结束时当前 warp 负责的每个 token 中需要的 K cache head 已经全被加载入 thread 本地的 k_vecs 中了.
由于一个 thread group 的 k_vecs 才能真正组成一个 head, 在退回第二个循环进行 QK dot 的时候, 需要做个 reduction, 具体的范围就是 THREAD_GROUP_SIZE 个 thread:
| |
计算完 qk 后, 由当前 thread group 中第一个 (offset 为 0) 的 thread 对自己刚才算出来的 qk 进行 mask, 顺便看看如果没有 mask 掉, 把 qk_max 赋值为 qk:
| |
🧐 为什么要做 mask?
- 因为一个 seq 的最后一个 PA block 可能覆盖不满
BLOCK_SIZE个 token. 这里的 mask 就是把那部分 qk 置零.
5.4. Softmax
我勒个 QK 啊, 总算算完了, 锐克 five 都要被抽清仓了. 页意丁真, 鉴定为开算 softmax.
主要步骤就是广播然后算, 算 softmax 需要知道每个 head 对应的 qk 的最大值. 由于一个 cuda block 负责的就是一个 head, 对于这个 head 上面的计算步骤一共算了 cache_len个 token 的 qk, 因此需要做一个 cuda block 范围的规约, 找到其中最大的 qk 值.
先在 warp 层面规约.
| |
red_smem是之前申请的 shared memory.VLLM_SHFL_XOR_SYNC是一个 warp 内的 shuffle 操作, 具体来说, 在每次循环时, 每个 thread 和自己相距mask位置的线程交换数据 (交换来的数据通过fmaxf比较), 并且mask会逐渐减半, 直到THREAD_GROUP_SIZE为止.lane表示当前 warp 中的线程索引.
接着再对每个 warp 的最大值进行规约, 由于每个 warp 的最大值都被存入了 red_smem 中, 所以只需要再次进行 shuffle 操作即可.
| |
此时, 第 1 个线程的 qk_max 就是当前 cuda block 中所有 warp 中最大的 qk 值. 将其广播给所有线程:
| |
在获得了 qk_max 后, 就可以计算 softmax 了:
| |
5.5. LV (Logits * Value)
上图展示了 LV 的计算过程, 主要区别是由于要计算 Logits 的 shape 可以表示为 (num_heads, num_seqs, cache_len), 而 V 的 shape 可以表示为 (num_heads, cache_len, head_size), 因此 LV 的矩阵乘法中, 每计算一个元素需要读取 logits 的一行和 V 的一列进行计算.
此时, 一个 cuda block 的职责从 “自 Q 中读取一个 head” 转变为 “计算 output 中的一个 head”.
🧐 为什么在计算 LV 时, 去掉了 thread group 的概念, 每个 thread 都被设定为每次读取 16B?
- 因为现在每计算一个元素, 需要的访存量更大, 因此给每个 thread 分配了更多的数据读取量. 也就是说,
V_VEC_SIZE比VEC_SIZE更大.
由于 cuda 访存模式按行读取更快, 所以实际的计算结果在遍历 PA block 时线程内部利用 accs 进行累计 (以实现与 V 的一列进行计算的行为):
| |
由于每个线程负责的累计部分不满一整行/列, 所以进行规约:
| |
最后写入到输出中:
| |